CheXGenBench
CheXGenBench: A Unified Benchmark For Fidelity, Privacy and Utility of Synthetic Chest Radiographs
🏆 Benchmark Leaderboard
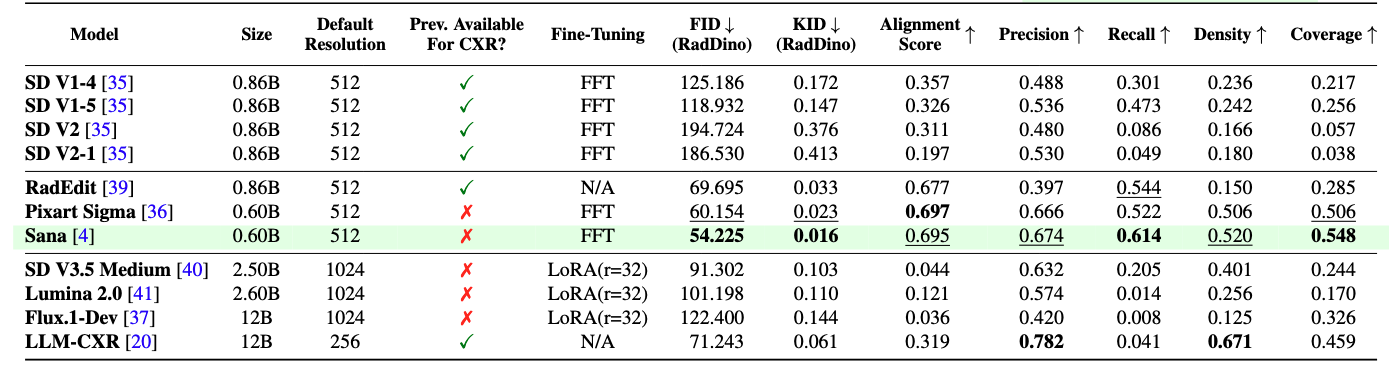
The following table ranks models based on the FID (RadDino) metric. Lower scores indicate better performance.
| Rank | Model | Size | FID (RadDino) $\downarrow$ | Year |
|---|---|---|---|---|
| 🥇 | Sana | 0.60B | 54.23 | 2025 |
| 🥈 | Pixart Sigma | 0.60B | 60.15 | 2024 |
| 🥉 | RadEdit | 0.86B | 69.70 | 2024 |
| 4 | LLM-CXR | 12B | 71.24 | 2024 |
| 5 | SD V3.5 Medium | 2.50B | 91.30 | 2024 |
| 6 | Lumina 2.0 | 2.60B | 101.20 | 2025 |
| 7 | SD V1-5 | 0.86B | 118.93 | 2022 |
| 8 | Flux.1-Dev | 12B | 122.40 | 2024 |
| 9 | SD V1-4 | 0.86B | 125.19 | 2022 |
| 10 | SD V2-1 | 0.86B | 186.53 | 2022 |
| 11 | SD V2 | 0.86B | 194.72 | 2022 |
Environment Setup
- Python>=3.10.0
- Pytorch>=2.0.1+cu12.1
git clone https://github.com/Raman1121/CheXGenBench.git conda create -n myenv python=3.10 conda activate myenv pip install -r requirements.txt
Adding a New Generative Model
The benchmark currently supports SD V1.x, SD V2.x, SD V3.5, Pixart Sigma, RadEdit, Sana (0.6B), Lumina 2.0, Flux.1-Dev, LLM-CXR.
In order to add a new model in the benchmark, follow these (easy) steps. Note: We assume that training of your T2I model is conducted separately from the benchmark.
-
To generate images for calculating quantitative metrics (FID, KID, etc), define a new function in the
tools/generate_data_common.pyfile that handles the checkpoint loading logic for the new model. -
Add a new
ifstatement in theload_pipelinefunction that calls this function. -
Add the generation parameters (num_inference_steps, guidance_scale, etc) in the
PIPELINE_CONSTANTSdictionary.
Generating Synthetic Data (Step 0)
In order to evaluate T2I models, the first step is to generate synthetic images using a fixed set of prompts. Follow these steps to generate synthetic images to be used for evaluation.
- Downloading Training Images: Download the MIMIC-CXR Dataset after accepting the license from here.
- Using LLaVA-Rad Annotations: We used LLaVA-Rad Annotations because of enhanced caption quality. They are presented in the
MIMIC_Splits/folder.cd MIMIC_Splits/unzip llavarad_annotations.zip- You will see the following CSV files
- Training CSV:
MIMIC_Splits/LLAVARAD_ANNOTATIONS_TRAIN.csv - Test CSV:
MIMIC_Splits/LLAVARAD_ANNOTATIONS_TEST.csv
- Training CSV:
- Data Organization: Use the
MIMIC_Splits/LLAVARAD_ANNOTATIONS_TEST.csvfile to generate images for evaluation. Follow the steps in the previous section to usetools/generate_data_common.pyscript to generate images. - Ensure that during generation, you save both the original prompt and the generated synthetic image in a CSV file (lets call it
prompt_INFO.csv). - Organize the synthetic data into a CSV file (
prompt_INFO.csv) with the following columns:'prompt': Contains the text prompt used for generation.'img_savename': Contains the filename (or path) of the saved synthetic image.
- File Placement: After generating all the synthetic images and creating the CSV file:
- Place the generated CSV file (
prompt_INFO.csv) in theassets/CSVdirectory. - Place all the generated synthetic image files in the
assets/synthetic_imagesdirectory.
- Place the generated CSV file (
Usage
This section provides instructions on how to use the benchmark to evaluate your Text-to-Image model’s synthetic data.
Quantitative Analysis: Generation Fidelity
The quantitative analysis assesses the synthetic data at two distinct levels to provide a granular understanding of its quality:
Overall Analysis: This level calculates metrics across the entire test dataset, consisting of all pathologies present in the MIMIC dataset. It provides a general indication of the synthetic data’s overall quality.
cd CheXGenBench
./scripts/image_quality_metrics.sh
Important Note: Calculating metrics like FID and KID can be computationally intensive and may lead to “Out of Memory” (OOM) errors, especially with large datasets (If using V100 GPUs or lower). If you encounter this issue, you can use the memory-saving version of the script:-
cd CheXGenBench
./scripts/image_quality_metrics_memory_saving.sh
The results would be stored in Results/image_generation_metrics.csv
Image-Text Alignment We calculate the alignment between a synthetic image and a prompt using the Bio-ViL-T model. Using this requires setting up a separate environment due to different dependencies.
- Create a new conda environment
himl - Navigate to health-multimodal repository and follow the instructions to install the required dependencies in
himl. - We have also provided a separate requirements file with the packages and their specific versions (untested).
conda activate himl pip install -r requirements_himl.txt
When the environment is set-up, run the following command:
./scripts/img_text_alignment.sh
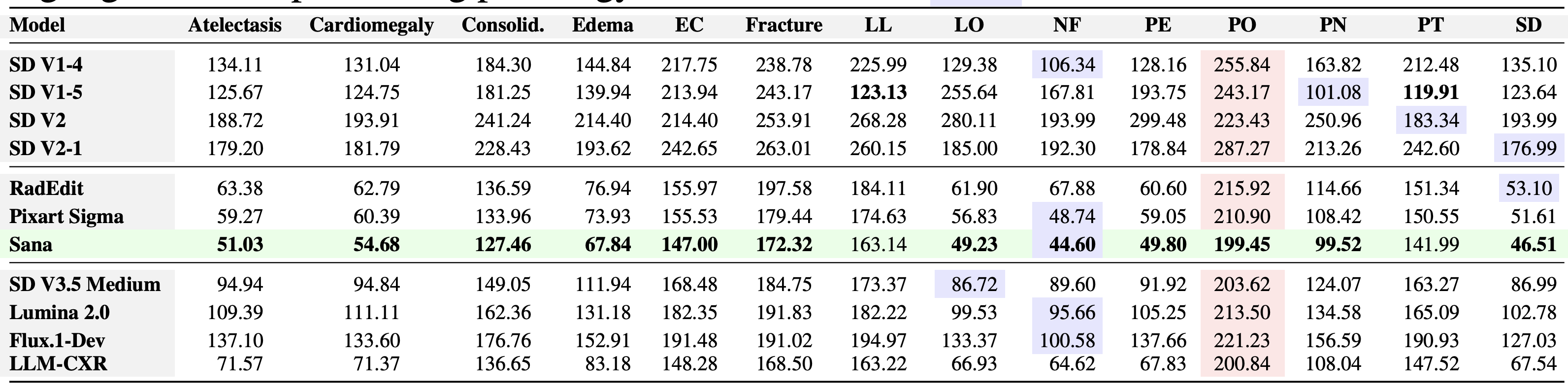
Conditional Analysis: This level calculates each metric separately for each individual pathology present in the dataset. This allows for a detailed assessment of how well the T2I model generates synthetic data for specific medical conditions.
cd CheXGenBench
./scripts/image_quality_metrics_conditional.sh
The results would be stored in Results/conditional_image_generation_metrics.csv
EXTRA_INFOargument when running the scripts (refer to the example scripts for specific usage).
Quantitative Analysis: Privacy Metrics

-
First, download the Patient Re-Identification Model from HERE and place it in
assets/checkpoints/folder. The name of the checkpoint is ResNet-50_epoch11_data_handling_RPN.pth. -
Set the appropriate paths and constants in the
scripts/privacy_metrics.shfile.
Run the following script to calculate privacy and patient re-identification metrics.
cd CheXGenBench
./scripts/privacy_metrics.sh
Quantitative Analysis: Downstream Utility
Image Classification
For image classification, we used 20,000 samples from the MIMIC Dataset for training. To evaluate, you first need to generate synthetic samples using the same 20,000 prompts with your T2I Model.
cd MIMIC_Splits/Downstream_Classification_Files
unzip training_data_20K.zip
- You can use the
tools/generate_data_common.pyfile to generate synthetic images. - During generation, save the synthetic images in a folder (let’s say
SYNTHETIC_IMAGES) - To run image classification using these images,
cd Downstream/Classification- Set the paths in
/scripts/run_training_inference.sh - Run
./scripts/run_training_inference.sh
Radiology Report Generation
To fine-tune LLaVA-Rad, the first step is creating a new environment following the steps mentioned in the official LLaVA-Rad repository.